Hi, I’m starting to write a blog post series about Kubernetes basics and this is Part 1. You can follow the guide to understand “What is Kubernetes?” and “What you can do with it?”.
What is Kubernetes?
Kubernetes is an open-source container orchestration tool for automating software deployment, management, and scaling smoothly and fast. The initial release was on June 7, 2014, by Google. Right now, the CNCF (Cloud Native Computing Foundation) is maintaining the project.
The Kubernetes is also called K8s. It’s working with Docker, Containerd, and CRI-O. If you want to use Kubernetes, I suggest you should know Docker before starting.
Basically, I can say, Kubernetes helps you manage containerized applications in different environments. You can run on physical servers (on-premise) and cloud and/or virtual machines as well.
What problems does Kubernetes solve?
When container technologies come through into our lives, the industry hyped “Monolith is old-school and, everybody should use container technologies and, you should separate all services in your application and switch to Microservices”
What does it mean? For example, you created an e-commerce web application and you should run every different part of the application separately. If the user searches for an item, the search mechanism should run by itself or the checkout system should be not dependent on the search mechanism. So, you should separate every different process of your application and divide them from each other.
The Kubernetes allow the run your every kind of different parts of the application. When something goes wrong with the search mechanism, the user also can checkout or go to the shopping cart because they are running individually and you just need to debug and fix the problem on the search mechanism.
You can follow the Microservices architecture on Google Cloud to understand the differences between Monolith and Microservices.
Which features offer Kubernetes?
- No downtime: It means, you will get a high-availability feature for your application and if something goes wrong in the production, your users can still access the application.-
- High performance: When you are started to get a heavy traffic load into the application, Kubernetes is scaling up the containers automatically and you don’t have any issues at the CPU, RAM, or Network Bandwidth bottleneck.
- Backup and Restore: The Kubernetes is always keeping the last state and when the server is gone or some bad thing happened the infrastructure has to have some kind of backup of the data and restore it.
The Kubernetes Components
Here are the most basic components of the Kubernetes. If you want to run a container with Kubernetes and want to play on your localhost, you should know them even if you are a developer.
Nodes and Pods
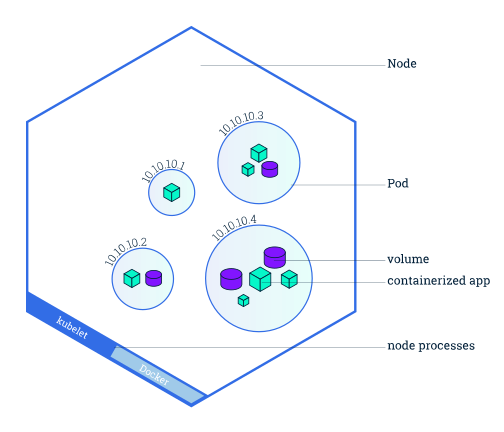
The node is just the server. It’ll be a physical server or any kind of cloud server or virtual machine.
The Pod is the smallest unit of Kubernetes and it’s an abstraction over the container. Pods are running in nodes and they are just containers or containers like Docker containers. Pods are using images and when you run the pod, the pods’ image comes from Docker Hub (https://hub.docker.com).
You don’t have to run your Kubernetes pods with Docker Hub, you can use any kind of public or private container image tool to keep your images.
Here is the important concept for the Kubernetes Nodes and Pods. The pod is usually meant to run one application container in the Node. You can run more than one pod in the node but usually, the case is one main container with a helper container or containers. For example, you can run nginx with redis and monitoring agent pods in the same Node.
The Kubernetes comes with its own network and you can see, that each pod gets its own local IP address like 10.10.10.2, 10.10.0.3, etc. Each pod can communicate using that IP address which is local IP. Kubernetes is also an important ephemeral concept it means that they can die very easily.
If you lost a pod for some reason and when Kubernetes re-cover the pod, the new pod should get a new IP address during the re-creation process. If you are communicating with the database and/or some kind of other services with the local IP, you will get into trouble! There is a really good way to cover this situation. Let’s see…
Service and Ingress
Service: Service can allow for a permanent IP address or static IP address that can be attached to each pod. Every pod has its own service and service means just the permanent or static IP, yes that’s it.
Pod and Service are running individually and when Pod dies and comes up with again or deployed a new version of the pod, the new pod immediately gets an IP of the service because the IP address is staying on the service.
Ingress: When the request comes to the node, first of all, the Ingress part is handling this request and then forwarding it to the service.
ConfigMap and Secrets
ConfigMap: Usually contains the configuration information like database URLs of database or some other services that you use. When the pod is starting, it gets the data that ConfigMap contains. We are most of the time calling them Environment Variable in the industry. ConfigMap is keeping all information as a plain-text and it’s not secure. Don’t store any kind of credentials like username or password in the ConfigMap.
Secrets: Secrets is also just like the ConfigMap but it stores data in base-64 encoded. The built-in security mechanism is not enabled by default on Kubernetes!
Volumes
If you planning to run your database into Kubernetes, you should set a persistent volume because Kubernetes doesn’t manage any data persistence. For example, when the pod is restarted or die, you will lose the all data because all data stayed in the pod and you didn’t mount any storage as a volume to your Kubernetes.
Volumes can be;
- On a local machine (Node)
- Remote (Outside of the K8s)
- Cloud Storage
Now, you know the basics about Kubernetes and I hope you enjoyed with this article! You can follow me on Twitter (https://twitter.com/flightlesstux) to know when Part 2 is coming…